
下推自动机PDA及上下文无关语言CFL
前言
阅读本文需要集合论、图论和数据结构的相关知识,在此不作有关相关知识的赘述。
笔者水平有限,存在的错误和不足请大家指正。
文法
文法的形式化定义
语言学家们在研究自然语言的理解的过程中完成了对 文法(grammar) 这一概念的形式化,通过找到一种自然语言的形式化的文法,可以有助于对这个语言的自动理解。例如可以用来帮助实现语言的机器翻译、文章摘要的提取、文稿的校对与更正等。现在给出文法的形式化定义:
文法$G$是一个四元组$G=(V,T,P,S)$,其中:
$V$是 变量(variable) 的非空有穷集,$\forall A\in V,A$被称为 语法变量(syntactic variable) ,简称变量,或称 终极符号(nonterminal) ,他表示一个 语法范畴(syntactic category) ,记作$L(A)$。
$T$是 终极符(terminal) 的非空有穷集,$\forall a\in T,a$被称为终极符,由于$V$中的符号表示语法范畴,所以有$V\cap T=\varnothing$。
$P$是 产生式(production) (或者称为 替换规则(substitution) )的非空有穷集,$P$中的元素均有形式$\alpha\rightarrow\beta$,称为产生式,读作$\alpha$定义为$\beta$,其中$\alpha\in(V\cup T)^+$,且$\alpha$中至少有$V$中的一个元素出现,$\beta\in (V\cup T)^ { * }$。其中$\alpha$被称为产生式$\alpha\rightarrow\beta$的 左部 ,而$\beta$称为产生式$\alpha\rightarrow\beta$的 右部 。产生式也被称为定义式或者语法规则。
$S\in V$被称作$G$的 开始符号(start symbol) 。
可以说文法的形式定义实际上给出了语言描述的一种模型。
为了方便描述,对于拥有相同左部的产生式$\alpha\rightarrow\beta_1,\alpha\rightarrow\beta_2,\cdots,\alpha\rightarrow\beta_n$,可以用更加简便的方式去描述它,写作$\alpha\rightarrow\beta_1|\beta_2|\cdots|\beta_n$,其中的$\beta_1,\cdots,\beta_n$被称作 候选式(candidate) 。
对于文法$G=(V,T,P,S)$,如果$\alpha\rightarrow\beta\in P,\gamma,\delta\in(V\cup T)^{ * }$,则称$\gamma\alpha\delta$在$G$中直接推导出$\gamma\beta\delta$,记作$\gamma\alpha\delta\Rightarrow_G\gamma\beta\delta$,读作$\gamma\alpha\delta$在文法$G$中直接推导出$\gamma\beta\delta$,可以简称直接推导为 推导(derivation) ,有时候也称作 派生 。与之对应的,也有 归约(reduction) 的概念,即指$\gamma\beta\delta$在文法$G$中直接归约成$\gamma\alpha\delta$,这是因为有产生式$\alpha\rightarrow\beta$。
很明显$\Rightarrow_G$是$(V\cup T)^{ * }$上的一个二元关系,那么可以对其作集合的相关运算,为了方便,我们用$\Rightarrow^+_G$表示正闭包$(\Rightarrow_G)^+$,用$\Rightarrow^ { * }_G$表示克林闭包$(\Rightarrow_G) ^ { * }$,用$\Rightarrow^n_G$表示幂运算$(\Rightarrow_G)^n$。在意义清楚的情况下也可以简写成$\Rightarrow,\Rightarrow^+,\Rightarrow^ { * },\Rightarrow^n$。类似的,对于归约的过程可以记作$\mapsto$表示,也有类似的简写记号。
从二元关系的合成的意义上来看,不难看出:
$\alpha\Rightarrow^n\beta$表示$\beta$在$G$中经过$n$步推导出$\beta$,也就是说存在$\alpha_1,\alpha_2,\cdots,\alpha_{n-1}\in(V\cup T)^{ * }$使得$\alpha\Rightarrow\alpha_1\Rightarrow\alpha_2\Rightarrow\cdots\Rightarrow\alpha_{n-1}\Rightarrow\beta$(这里是一种简写的表示,也可以称这样一个替换序列为 派生(derivation) ),对于归约而言也有相应的含义。当$n=0$时也就是说有$\alpha=\beta$。
$\alpha\Rightarrow^ +\beta$表示$\beta$在$G$中经过至少$1$步推导出$\beta$,对于归约而言也有相应的含义。
$\alpha\Rightarrow^ { * }\beta$表示$\beta$在$G$中经过若干步推导出$\beta$,对于归约而言也有相应的含义。
现在给出一个文法的案例以供理解:
设有文法$G=(${$S,A,B$}$,${$0,1$},{$S\rightarrow A|AB,A\rightarrow 0|0A,B\rightarrow 1|11,S$}$)$,那么$S$在$G$中可以推导出$00011$:
- $S\Rightarrow AB$,使用产生式$S\rightarrow AB$
- $AB\Rightarrow 0AB$,使用产生式$A\rightarrow 0A$
- $0AB\Rightarrow 00AB$,使用产生式$A\rightarrow 0A$
- $00AB\Rightarrow 000B$,使用产生式$A\rightarrow 0$
- $000B\Rightarrow 00011$,使用产生式$B\rightarrow 11$
上文使用文法得到了一个句子,这说明文法可以用于产生语言,现在给出定义:
设有文法$G=(V,T,P,S)$,则称$L(G)=${$w|w\in T^ { * },S\Rightarrow^{ * }w$}为$G$产生的 语言 ,$\forall w\in L(G),w$称为$G$产生的一个 句子(sentence) 。而对于$\forall\alpha\in(V\cup T)^{ * }$,如果有$S\Rightarrow^ { * }$,那么称$\alpha$是$G$产生的一个 句型(sentential form) 。不难发现句子不能含有语法变量,而句型可以含有语法变量。
关于文法也可以由此引入 等价(equivalence) 的概念,也就是说对于文法$G_1,G_2$,如果有$L(G_1)=L(G_2)$,那么称它们等价。
上面的这个案例文法所产生的语言$L(G)=L(0^ { * }(\epsilon+1+11))$(这里使用了正则表达式),也就是说$L(G)$是一个$RL$,但不能说文法产生的语言都是$RL$,很容易可以举出文法$G=(${$A$},{$0,1$},{$A\rightarrow 01|0A1$}$,A)$,它所产生的语言是{$0^n1^n|n\geq 1$},根据正则语言的泵引理,可以发现它不是一个$RL$,为了更好地分析形式文法,可以引入文法的 乔姆斯基体系(Chomsky hierarchy) 。
乔姆斯基体系
设有文法$G=(V,T,P,S)$,那么有:
- $G$被称为 0型文法(type 0 grammar) ,或者 短语结构文法(phrase structure grammar,PSG) 。对应地,$L(G)$也被称为 0型语言 或者 短语结构语言(PSL) 、 递归可枚举集(recursively enumerable set,r.e.) 。
- 如果对于$\forall\alpha\rightarrow\beta\in P$,均有$|\beta|\geq|\alpha|$成立,则称$G$为 1型文法(type 1 grammar) ,或者 上下文有关文法(context sensitive grammar,CSG) 。对应地,$L(G)$也被称为 1型语言(type 1 language) 或者 上下文有关语言(context sensitive language,CSL) 。
- 如果对于$\forall\alpha\rightarrow\beta\in P$,均有$|\beta|\geq|\alpha|$,并且有$\alpha\in V$成立,则称$G$为 2型文法(type 2 grammar) ,或者 上下文无关文法(context free grammar,CFG) 。对应地,$L(G)$也被称为 2型语言(type 2 language) 或者 上下文无关语言(context free language,CFL) 。
- 如果对于$\forall\alpha\rightarrow\beta\in P$,$\alpha\rightarrow\beta$均有形式$A\rightarrow w,A\rightarrow wB$,这里的$A\rightarrow wB$也可以都换成$A\rightarrow Bw$的形式(符合前者的被称为 右线性文法(right liner grammar) ,符合后者的被称为 左线性文法(left liner grammar) ,两者混用可以生成3型语言以外的语言),其中$A,B\in V,w\in T^ { + }$,则称$G$为 3型文法(type 3 grammar) ,或者 正则文法(regular grammar,RG) 、 正规文法 。对应地,$L(G)$也被称为 3型语言(type 3 language) ,而它产生的语言正好是 正则语言(regular language,RL) ,或者称为 正规语言 。
但是先前已经定义RL是DFA识别的语言,为了解释这个矛盾,现在对这个事实进行证明:
RL能被RG产生:
设有$DFA$:$M=(Q,\Sigma,\delta,q_0,F)$,可以构造$G$使得它是一个RG且有$L(G)=L(M)-${$\epsilon$},考虑$G=(Q,\Sigma,${$q\rightarrow ap| \delta(q,a)=p$}$\cup${$q\rightarrow a| \delta(q,a)=p\in F$}$)$。
RG产生的语言是RL:
对于一个RG:$G=(V,T,P,S)$,假设$Z\notin V$,它表示$FA$的终止状态,可以作一个$FA$:$M=(V\cup${$Z$}$,T,\delta,S,${$Z$}$)$,其中$\delta的$定义为:
对于$\forall(A,a)\in V\times T$,如果$A\rightarrow a\in P$那么有$\delta(A,a)=${$B|A\rightarrow aB\in P$}$\cup${$Z$};如果$A\rightarrow a\notin P$那么有$\delta(A,a)=${$B|A\rightarrow aB\in P$}。
综上所述,RG产生的语言就是RL。
显然,按照PSG、CSG、CFG、RG的顺序一直往后,文法的限制条件也就越多,后面的文法类型中的文法一定也属于前面的文法类型,可以用韦恩图表示(部分语言类之间的关系在后文中将会进一步探究):
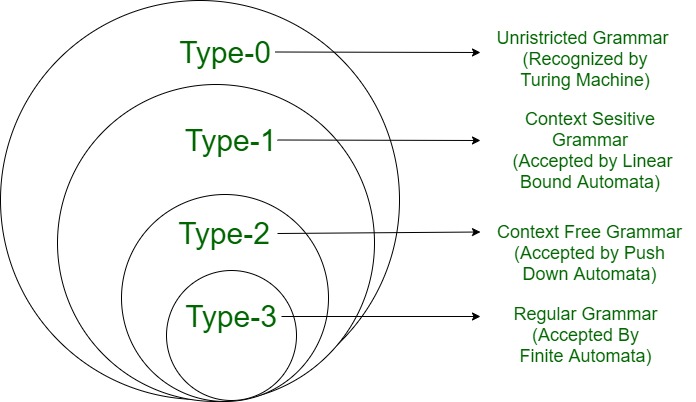
前文中给出了两个文法,由定义可以知道它们分别为RG和CFG,现在给出其他两种类型的文法的例子:
$G=(${$S,A,B,C$},{$a,b,c$},{$S\rightarrow aBC|aSBC,CB\rightarrow BC,aB\rightarrow ab,bB\rightarrow bb,bC\rightarrow bc,cC\rightarrow cc$}$,S)$,这是一个CSG,可以证明$L(G)=${$a^nb^nc^n|n\geq 1$}。
$G=(${$S$},{$0$},{$S\rightarrow ABC,ABC\rightarrow 0$}$,S)$,这是一个PSG,$L(G)=${$0$},显而易见的可以构造出一个RG:$G’=(${$S$},{$0$},{$S\rightarrow 0$}$,S)$使得$L(G’)=${$0$},也就是说不同类型的文法之间也可以等价。
按照上述的对四种文法的定义,不难发现RG、CFG和CSG生成的语言都不含有$\epsilon$。为了方便研究,称形如$A\rightarrow\epsilon$的产生式为 空产生式 ,或者称为$\epsilon$产生式,在RG、CFG和CSG的限制中允许出现空产生式,这样就允许它们产生的语言中也含有$\epsilon$。
在引入了空产生式的概念后,不难发现如果$L$是RL、CFL或者CSL,那么$L\cup${$\epsilon$}依旧是RL、CFL、CSL。同时如果$L$是RL、CFL或者CSL,那么$L-${$\epsilon$}依旧是RL、CFL、CSL。
上下文无关文法
上下文无关文法的相关概念
上下文无关文法在程序设计语言的规范化及编译中有重要应用。程序设计语言的文法犹如外语语法参考书,设计人员在编写程序设计语言的编译器和解释器时,常需要先获取该语言的文法。大多数编译器和解释器都包含一个 语法分析器(parser) ,它在生成编译代码或解释程序执行前,提取出程序的语义。上下文无关语言使得构造语法分析器的工作变得容易,某些工具甚至能根据文法自动地生成语法分析器。
CFL之所以被称作上下文无关,是指在文法派生的每一步$\alpha A\beta\Rightarrow\alpha\gamma\beta$中$\gamma$仅根据$A$的产生式派生,而无需依赖$A$的上下文$\alpha$和$\beta$。
为了更好地理解CFL,首先给出一个CFG的例子:
有文法$G=(${$A,B$},{$0,1,$#},{$A\rightarrow 0A1|B,B\rightarrow$#}$)$,它生成字符串$0000$#$111$的派生过程如下:
$A\Rightarrow 0A1\Rightarrow 00A11\Rightarrow 000A111\Rightarrow 000B111\Rightarrow 000$#$111$,为了生动形象地描述派生过程,可以使用 语法分析树(parse tree) ,这样便可以从树中看出整个派生过程和最终产生的字符串:
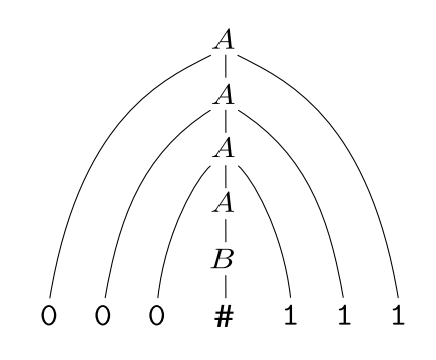
现在给出语法分析树的形式化定义,对于一个CFG:$G=(V,T,P,S)$而言,它的语法分析树是这样的一棵树:它的每一个内节点的标记是$V$中的变元符号;每一个叶节点的标记是$V\cup T\cup${$\epsilon$}中的符号;如果内结点的标记是$A$,它的子节点从左至右分别为$X_1,X_2,\cdots,X_n$,那么$A\rightarrow X_1X_2\cdots X_n$肯定是$P$的一个产生式,如果某个$X_i$是$\epsilon$,那么$X_i$一定是$A$唯一的子节点,且$A\rightarrow\epsilon$是一个产生式。
将语法分析树的全部叶节点从左到右连接起来,称为该树的 产物(yield) 或结果。如果树根节点是初始符号$S$,叶节点是终结符,显然该树的产物属于$L(G)$。
语法分析树种标记为$A$的内节点及其全部子孙节点构成的子树,称为$A$子树。
利用数学归纳法可以证明这样一个定理:设有CFG:$G=(V,T,P,S)$且$A\in V$,那么文法$G$中有$A\Rightarrow^{ * }$当且仅当在文法$G$中存在以$A$为根节点、产物为$\alpha$的语法分析树。
有时候在一个文法中能够用多种不同的方式产生出同一个字符串,在此提供一个案例:
设有文法$G_{exp}=(${$E,I$},{$a,b,+,* ,(,)$},{$E\rightarrow I|E+E|E *E|(E),I\rightarrow a$}$,E)$,这个文法可以用于生成一个含有加法和乘法的代数表达式。但是如果使用这个文法生成字符串$a+a *a$可以发现有多种派生:
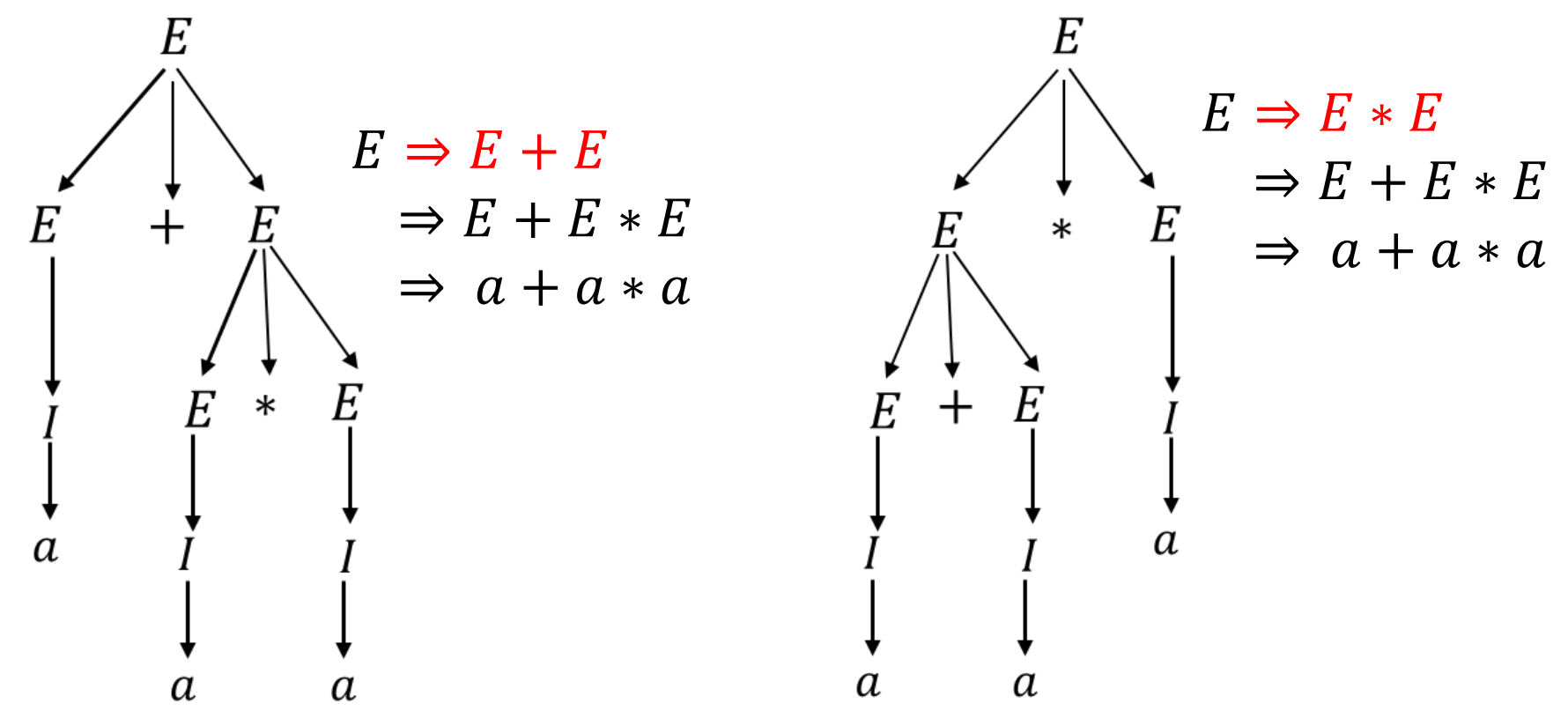
右边的派生很明显不符合数学运算的优先级要求,通过语法分析树可以很明显地看出在派生的过程中产生了歧义,为了形式化歧义的概念,首先给出最左派生的概念:
对于文法$G$中的一个字符串$w$的派生,如果在每一步都是替换最左边剩下的变元,则称这个派生是 最左派生(leftmost derivation) ,类似的也有最右派生。分别记为$\Rightarrow_{lm}^{ * },\Rightarrow_{rm}^{ * }$,显然任何派生都有等价的最左派生和最右派生,也就是说$A\Rightarrow^{ * }w$当且仅当$A\Rightarrow_{lm}^{ * }w$当且仅当$A\Rightarrow_{rm}^{ * }w$。
结合先前介绍的语法分析树,实际上可以证明如果$\alpha$是某个CFG的句型,那么$\alpha$的派生树与最右派生和最左派生是一一对应的,但是这棵语法分析树可以对应多个不同的派生。
现在给出歧义的形式概念:
如果字符串$w$在上下文无关文法$G$中有两个或两个以上不同的最左派生,则称$G$ 歧义地(ambiguously) 产生字符串$w$,如果文法$G$歧义地产生某个字符串,则称$G$是 歧义的(ambiguous) 。
上文作出的文法$G_{exp}$有两个不同的语法分析树,所以它是一个歧义的文法,但是实际上可以作出等价的非歧义文法,现在给出等价的非歧义文法:
$G_{exp’}=(${$E,F,I,T$},{$a,b,+,* ,(,)$},{$E\rightarrow E+T|T,T\rightarrow T* F|F,F\rightarrow (E)|I,I\rightarrow a$}$,E)$
但是并非是所有歧义文法都能找到等价的非歧义文法,这样的文法被称为是固有歧义的(inherently ambiguous) 。例如{$a^ib^jc^k|i=j或j=k且i,j,k\geq 0$}便是固有歧义的,在后文会对这一定理进行证明。
CFG的化简
在构造CFG的过程中,有时由于某种原因,文法中出现的符号以及使用的产生式并不一定是恰当的,比如下列两个文法实际上是等价的:
$G_1=(${$S,A,B,C,D,E$},{$0,1,2,$},{$S\rightarrow 0|0A|E,A\rightarrow\epsilon|0A|1A|B,B\rightarrow $$ C,C\rightarrow 0|1|0C|1C,D\rightarrow 1|1D|2D,E\rightarrow 0E2|E02$}$,S)$
$G_2=(${$S,A,C$},{$0,1,$},{$S\rightarrow 0|0A,A\rightarrow 0|1|0A|1A|$$ C,C\rightarrow 0|1|0C|1C$}$,S)$
为了便于便于分析和解决问题,以不改变语言为前提,化简文法和限制文法的格式,现在介绍化简上下文无关语言的三个组成部分:
- 消除无用符号(useless symbols):对文法定义的语言没有贡献的符号(不出现在任何由开始符号在任何由开始符号推导出一个终结符串的过程中的变元或终结符)
- 消除$\epsilon$产生式:也就是消除$A\rightarrow\epsilon$,这样得到的语言将会是$L-${$\epsilon$}
- 消除单元产生式(unit productions):$A\rightarrow B$,其中$A$和$B$都是变量。
对于CFG:$G=(V,T,P,S),X\in V\cup T$:
如果$S\Rightarrow^{ * }\alpha X\beta$,则称$X$是可达的(reachable)。
如果$X\Rightarrow^{ * }w,w\in T^{ * }$,称$X$是产生的(generating)。
如果$X$同时是产生的和可达的,也就是说$S\Rightarrow^{ * }\alpha X\beta\Rightarrow^{ * }w,w\in T^{ * }$,则称$X$是有用的,否则称$X$为无用符号。
存在一种方法得到产生的符号的集合和可达的符号的集合:
- 产生的:每一个$T$中的符号都是产生的;如果$A\rightarrow\alpha\in P$且$\alpha$中的符号都是产生的,那么$A$也是产生的。
- 可达的:$S$是可达的;如果$A\rightarrow\alpha\in P$且$A$是可达的,则$\alpha$中的符号都是可达的。
结论是显然的,在此不作证明。在得到了这两个集合后删掉全部含有“非产生的”和“非可达的”符号的产生式即可。
可以证明,每一个非空的CFL都可以用一个不带无用符号的CFG定义。
注意:在消除无用符号的过程中要先寻找并消除全部非“产生的”符号,再寻找并消除全部非“可达的”符号,否则可能会出现消除不完整的情况,下面给出一个例子:
设有文法$G=(${$S,A,B$},{$a,b$},{$S\rightarrow AB|a,A\rightarrow b$}$,S)$
- 先消除非可达的:可达的符号集为{$S,A,B,a,b$},故无消除符号。
- 再消除非产生的:产生的符号集为{$a,b,S,A$},消除$B$得到$G’=(${$S,A,B$},{$a,b$},{$S\rightarrow a,A\rightarrow b$}$,S)$。
显然依旧存在无用符号。
如果按照相反的顺序可以发现不会存在无用符号:
- 先消除非产生的:产生的符号集为${a,b,S,A}$,消除$B$得到$P={S\rightarrow a,A\rightarrow b}$。
- 再消除非可达的:可达的符号集为${S,a}$,消除${b,A}$得到$P={S\rightarrow a}$。
实际上可以证明先消除全部非“产生的”符号,再寻找并消除全部非“可达的”符号可以得到不存在无用符号的文法,在此不作证明。
如果变元$A$满足$A\Rightarrow^{ * }\epsilon$,则称$A$是可空的。现在给出一个确定可空变量的方法:
如果$A\rightarrow\epsilon\in P$,那么$A$是可空的;如果$B\rightarrow\alpha\in P$且$\alpha$中的每一个符号都是可空的,则$B$是可空的。
在确定了可空变量后,给出一种替代方案:
将含有可空变量的一条产生式$A\rightarrow X_1X_2\cdots X_n$用一组产生式$A\rightarrow Y_1Y_2\cdots Y_n$代替,其中:
- 若$X_i$不是可空的,那么$Y_i$为$X_i$。
- 若$X_i$是可空的,$Y_i$为$X_i$或者$\epsilon$(也就是说对于每一个可空变量,它可以出现或不出现在替换后的产生式中)。
- 但是不能出现$Y_i$全为$\epsilon$的情况。
满足这样的替代方案的情况下,再消除文法中的$\epsilon$产生式,便可以得到语言$L-${$\epsilon$},下面给出一个例子作为说明:
设有文法$G=(${$S,A,B$},{$a,b$},{$S\rightarrow AB,A\rightarrow AaA|\epsilon,B\rightarrow BbB|\epsilon$}$)$。
首先可以确定可空的变量是{$S,A,B$}。
替换全部带有可空变量的表达式:$S\rightarrow AB$替换成$S\rightarrow AB|A|B$,$A\rightarrow AaA|\epsilon$替换成$A\rightarrow AaA|Aa|aA|a$,$B\rightarrow BbB|\epsilon$替换成$B\rightarrow BbB|Bb|bB|b$。
如果两个变量满足$A\Rightarrow^{ * }B$,则称$[A,B]$为单元对,现在给出一种确定单元对的方法:
- 如果$A\rightarrow B\in P$,则$[A,B]$是单元对。
- 如果$[A,B],[B,C]$都是单元对,那么$[A,C]$也是单元对。
消除单元产生式的过程要求删除全部形如$A\rightarrow B$的单元产生式,并且对每一个单元对$[A,B]$,将$B$的产生式的右部复制给$A$作为产生式。
下面给出一个例子作为说明:
设有文法$G=(${$S,A,B$},{$0,1$},{$S\rightarrow A|B|0S1,A\rightarrow 0A|0.B\rightarrow 1B|1$}$,S)$
确定单元产生式:$S\rightarrow A,S\rightarrow B$,非单元产生式$S\rightarrow 0S1.A\rightarrow 0A|0,B\rightarrow 1B|1$。
将单元产生式代入非单元产生式:$A\rightarrow 0A|0$代入$S\rightarrow A$得到$S\rightarrow 0A|0$,$B\rightarrow 1B|1$代入$S\rightarrow B$得到$S\rightarrow 1B|1$。
可以证明化简CFG有一个可靠的顺序是:
- 消除$\epsilon$产生式。
- 消除单元产生式。
- 消除非产生的无用符号。
- 消除非可达的无用符号。
也就是说每一个不带$\epsilon$的CFL都可以由一个不带无用符号、$\epsilon$产生式和单元产生式的文法来定义,在此不对这一定理进行证明。
乔姆斯基范式和格雷巴赫范式
不难发现,RG是相当规范的,CFG的形式相较于RG而言并没有这样规范,在完成了对CFG的化简后,还需要进一步找到与之等价的规范文法,这里将要介绍两种规范的文法。
乔姆斯基范式(Chomsky normal form,CNF) :一个CFG:$G=(V,T,P,S)$的每一个产生式的形式都为$A\rightarrow BC$或$A\rightarrow a$,其中$A,B,C\in V,a\in T$。不难发现利用CNF派生长度为$m$的字符串,刚好需要$m+(m-1)=2m-1$步。
现在给出将一个不带$\epsilon$的CFG转换成CNF的方法:
先前已经介绍了如何得到不带无用符号、$\epsilon$产生式和单元产生式的CFG的方法,这里已经事先进行了化简。
考虑文法中每一个形式为$A\rightarrow X_1X_2\cdots X_m,m\geq 2$的产生式,若$X_i$为终结符$a$,则引进新变量$C_a$替换$X_i$并增加新产生式$C_a\rightarrow a$。
现在需要进行替换的产生式的形式将会变为$A\rightarrow B_1B_2\cdots B_m,m\geq 3$和$B_i\rightarrow a$。
对于$A\rightarrow B_1B_2\cdots B_m,m\geq 3$,可以引入新变量$D_1,D_2,\cdots,D_{m-2}$将其替换成一组产生式$A\rightarrow B_1D_1,D_1\rightarrow B_2D_2,\cdots,D_{m-2}\rightarrow B_{m-1}B_m$,这样就把CFG变成了CNF的形式。
在这里给出一个例子以供理解:
设有CFG:$G=(${$S,A,B$},{$a,b$}$,P,S)$,其中$P=${$S\rightarrow bA|aB,A\rightarrow bAA|aS|a,B\rightarrow aBB|bS|b$},可以得到与其等价的CNF:$G’=(${$S,A,B,D_a,C_b,D_1,D_2$},{$a,b$}$,P’,S)$,其中$P’=${$S\rightarrow C_bA|C_aB,A\rightarrow C_bD_1|C_aS|a,B\rightarrow C_aD_2|C_bS|b,D_1\rightarrow AA,D_2\rightarrow BB,C_a\rightarrow a,C_b\rightarrow b$}。
格雷巴赫范式(Greibach normal form,GNF) :一个CFG:$G=(V,T,P,S)$的每一个产生式的形式都为$A\rightarrow a\alpha$,其中$A\in V,a\in T,\alpha\in V^{ * }$。不难发现GNF每个产生式都会引入一个终结符,利用GNF派生长度为$m$的字符串,刚好需要$m$步。
先前已经证明了不带$\epsilon$的CFG可以转换成CNF,作出与CNF等价的GNF是非常简单的,在此不作说明。也就是说由一个不带$\epsilon$的CFG可以转换成GNF。
下推自动机
下推自动机的引入
先前已经介绍了FA,它识别的语言是RL,有着重要的作用,但是在现实中存在着不少只使用FA无法解决的问题,考虑这样一个问题:
括号匹配问题:要求设计一台自动机识别字母表为$(,),[,],{,}的字符串,当它是合法的括号匹配的时候就接受这个字符串,例如[[]]就是一个合法的括号匹配,而[(])是一个非法的括号匹配。
但是使用FA是没有办法解决这个问题的,设这个语言是$L_1$,考虑语言$L_2={(^{ * })^{ * }}$,可知$L_1\cap L_2=${$(^n)^n|n\geq 0$},利用正则语言的泵引理可以知道它不是一个RL,所以无法设计一个FA满足问题需求。
在现实中很容易使用C语言编写程序解决这个问题:
|
|
在上述的程序中,使用了 栈(stack) 这一结构,如果给FA添加上一个栈会发生什么呢?这就引出了 下推自动机(pushdown automata,PDA) 这一计算模型,相较于FA,它还有一个栈作为额外设备,栈在控制器的有限存储量之外提供了附加的存储,使得下推自动机能够识别某些非正则语言,实际上下推自动机在能力上和CFG是等价的。
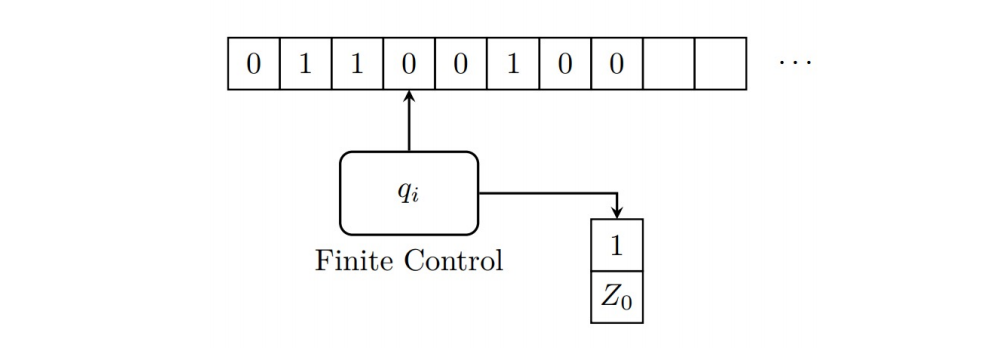
简单地说,下推自动机可以看成是$\epsilon-NFA$和栈的结合,它的下一步动作由三个要素决定:
- 当前$\epsilon-NFA$的状态
- 当前的输入符号(或者是$\epsilon$)
- 当前的栈顶符号
$\epsilon-NFA$有着有限状态、非确定性、空转移的性质;栈是一种先进后出(First In Last Out,FILO)的结构,在这里只使用栈顶且栈的长度是无限的,栈有两种操作:弹栈(Pop)也就是仅弹出栈顶的一个符号,压栈(Push)也就是压入一串符号。
运转过程:
控制器从输入带读入一个符号$a$,控制栈弹出一个栈顶符号$Z$。
根据符号$a,Z$和当前所处的状态进行状态的转移并对栈压入$0$个符号(也就相当于是Pop)或者压入一个符号串(也就相当于是Push)。
下推自动机的形式化定义
现在给出PDA的形式化定义:
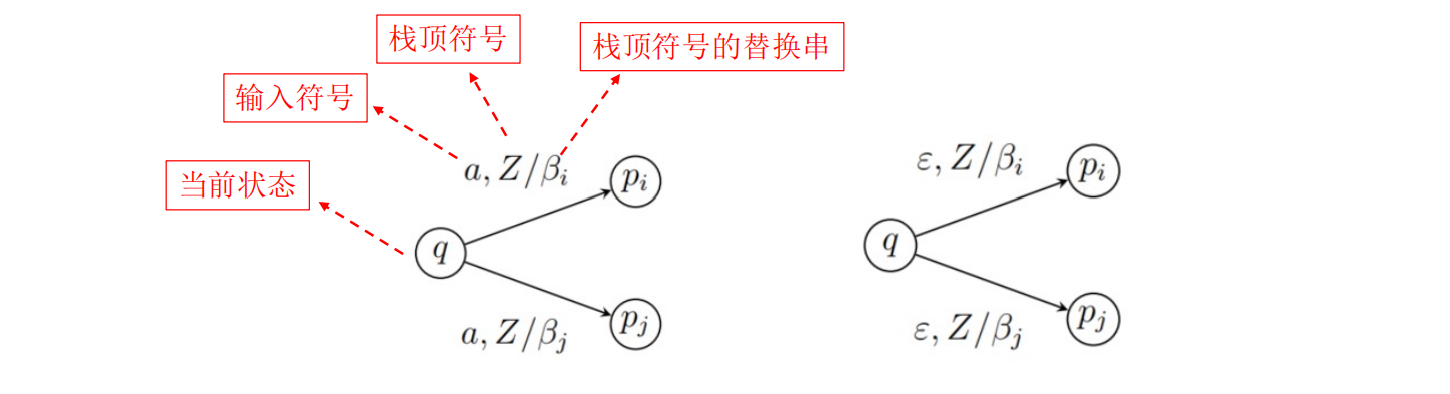
下推自动机$P$是一个七元组$(Q,\Sigma,\delta,q_0,Z_0,F)$,其中:
- $Q$是有穷状态集,相应的有状态的概念。
- $\Sigma$是有穷输入符号集(input alphabet),要求$M$的输入字符串都是$\Sigma$上的字符串,常使用小写字母表示输入的字符串。
- $\Gamma$是有穷栈符号集(stack alphabet),里面的符号被称为栈符号(stack symbols),常使用大写字母表示栈中的符号,用希腊字母表示栈字符串。
- $\delta:Q\times(\Sigma\cup{\epsilon})\times\Gamma\rightarrow 2^{Q\times\Gamma^{ * }}$是状态转移函数。可知对于$(q,a,X)\in Q\times(\Sigma\cup\epsilon)\times\Gamma,\delta(q,a,X)={(p_1,\gamma_1),(p_2,\gamma_2),\cdots,(p_m,\gamma_m)}$,根据当前的$a$和$X$,可以将当前状态由$q$转移到$p_1$,再用$\gamma_1$代替栈顶的$X$。如果$\gamma_1=\epsilon$则弹出$X$,如果$\gamma_1=\epsilon$则弹出$X$,如果$\gamma_1=X$那么栈顶符号依旧为$X$,如果$\gamma_1=Z_1Z_2\cdots Z_k$那么弹出$X$再依次压入$Z_k,Z_{k-1},\cdots,Z_1$。
- $_0\in Q$是初始状态。
- $Z_0\in\Gamma$是初始栈底符号(start stack symbol),是中国自动机启动的时候栈内唯一的一个符号,用来标志栈底。
- $F\subseteq Q$是接受状态集。
也可以使用状态转移图来表示PDA:
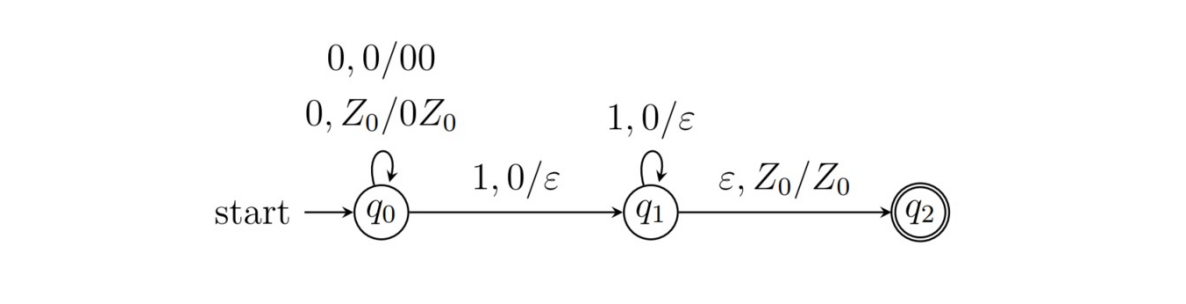
由正则语言的泵引理可知{$0^n1^n|n\geq 1$}不能被FA识别,但是可以构造一个PDA识别它:
为了方便说明,现在引入一些概念:
设有PDA:$M=(Q,\Sigma,\Gamma,\delta,q_0,Z_0,F)$,$\forall(q,w,\gamma)\in Q\times\Sigma^{ * }\times\Gamma^{ * }$称为是$M$的一个 即时描述(instantaneous descriptin,ID) 。它表示:$M$处于状态$q$;$w$是剩余的未处理的输入字符串,而且此时$M$正在注视$w$的首字符;栈中的符号串为$\gamma$,$\gamma$的最左符号为栈顶符号,越靠右越在栈的较下面。
在PDA的一个动作下,会发生从ID$\ I$到ID$\ J$的变化,称之为ID的转移。
具体的,如果$(p,\beta)\in\delta(q,a,Z)$,由$(q,aw,Z\alpha)$到$(p,w,\beta\alpha)$的变化称为ID的转移$\vdash_P$,在不引发混淆的情况下可以记作$\vdash$,这样ID的转移就可以写为$(q,aw,Z\alpha)\vdash(p,w,\beta\alpha)$,这是一个二元关系,相应地也可以作出它的克林闭包,为了方便,使用$I\vdash^{ * }J$表示$I(\vdash)^{ * }J$
显然在PDA的ID的转移过程中可以会存在多条转移路径,但是最终只有一条正确的路径可以进入接受状态。
PDA接受的语言
下推自动机接受一个语言有着不同的方式,现在对此进行介绍:
设有PDA:$P=(Q,\Sigma,\Gamma,\delta,q_0,Z_0,F)$,要求$F\neq\varnothing$,称通过终态方式接受的语言$L(P)=${$w|(q_0,w,Z_0)\vdash^{ * }(p,\epsilon,\gamma),p\in F$},即能够使PDA到达终态的符号串的集合。
设有PDA:$P=(Q,\Sigma,\Gamma,\delta,q_0,Z_0,F)$,要求$F=\varnothing$,称通过空栈方式接受的语言$N(P)=${$w|(q_0,w,Z_0)\vdash^{ * }(p,\epsilon,\epsilon)$},即能够使PDA的栈变空的符号串的集合。
现在证明这两种接受方式的下推自动机是可以相互转换的:
先证明对于任意PDA$\ M_1$,存在PDA$\ M_2$使得$N(M_2)=L(M_1)$:
设有PDA$\ M_1=(Q,\Sigma,\Gamma,\delta_1,q_{01},Z_{01},F)$,考虑构造PDA$\ M_2=(Q\cup${$q_{02},q_e$}$,\Sigma,\Gamma\cup${$Z_{02}$}$,\delta,q_{02},Z_{02},F)$,其中要求$Q\cap{q_{02},q_e}=\Gamma\cap${$Z_{02}$}$=\varnothing$,而具体地,$\delta_2$的定义如下:
- 在$M_2$启动后立马进入$M_1$的初始ID,也就是说$\delta_2(q_{02},\epsilon,Z_{02})={q_{01},Z_{01}Z_{02}}$。
- 让$M_2$完全模拟$M_1$的非空移动:$\forall (q,a,Z)\in Q\times\Sigma\times\Gamma$有$\delta_2(q,a,Z)=\delta_1(q,a,Z)$。
- 当$M_2$在非终止状态下完全模拟$M_1$的空移动:$\forall (q,Z)\in(Q-F)\times\Gamma$有$\delta_2(q,\epsilon,Z)=\delta_1(q,\epsilon,Z)$。
- 在$M_1$的终止状态下,$M_2$除了模拟$M_1$的空移动外,还需要模拟$M_1$的“接受动作”,由于在此动作后栈可能不是空的,进入清栈状态:$\forall(q,Z)\in F\times\Gamma,\delta_2(q,\epsilon,Z)=\delta_1(q,\epsilon,Z)\cup${$(q_e,\epsilon)$}。
- $M_1$的栈已空,并且已经进入了终止状态,所以$M_2$进入清栈状态$q_e$并将栈清空:$\forall q\in F,\delta_2(q,\epsilon,Z_{02})\rightarrow${$(q_e,\epsilon)$}。
- $M_2$进行清栈工作:$\forall Z\in\Gamma\cup${$Z_{02}$}$,\delta_2(q_e,\epsilon)=${$(q_e,\epsilon)$}。
再证明对于任意PDA$\ M_1$,存在PDA$\ M_2$使得$L(M_2)=N(M_1)$:
设有PDA$\ M_1=(Q,\Sigma,\Gamma,\delta_1,q_{01},Z_{01},F)$,考虑构造PDA$\ M_2=(Q\cup${$q_{02},q_f$}$,\Sigma,\Gamma\cup${$Z_{02}$}$,\delta,q_{02},Z_{02},${$q_{02}$}$)$,其中要求$Q\cap${$q_{02},q_e$}$=\Gamma\cap${$Z_{02}$}$=\varnothing$,而具体地,$\delta_2$的定义如下:
- 在$M_2$启动后立马进入$M_1$的初始ID,也就是说$\delta_2(q_{02},\epsilon,Z_{02})={q_{01},Z_{01}Z_{02}}$。
- 让$M_2$完全模拟$M_1$的移动:$\forall(q,a,Z)\in Q\times(\Sigma\cup${$\epsilon$}$)\times\Gamma$有$\delta_2(q,a,Z)=\delta_1(q,a,Z)$。
- 当$M_1$的栈已空时,$M_2$的栈底符号成为栈中唯一的符号。因此要让$M_2$进入终止状态:$\delta_2(q,\epsilon,Z_{02})=${$(q_f,\epsilon)$}。
PDA与CFG的等价性
实际上PDA和CFG是等价的,现在对这一定理作出证明。
对于任何CFL$\ L$,一定存在PDA$\ P$使$L=N(P)$。
证明:对于一个CFG$\ G=(V,T,P’,S)$,可以构造这样的PDA$\ P_N=(${$q$}$,T,V\cup T,\delta,q,S,\varnothing)$,其中对于$\forall A\in V,\delta(q,\epsilon,A)=${$(q,\beta)|A\rightarrow\beta\in P’$},对于$\forall a\in T,\delta(q,a,a)=${$(q,\epsilon)$}。
可以证明$S\Rightarrow^{ * }\Leftrightarrow(q,w,S)\vdash^{ * }(q,\epsilon,\epsilon)$,也就是说$L(G)=N(P)$,在此不作详细证明。
对于任何PDA$\ P$,一定存在CFL$ L$使$L=L(P)$。
证明:了方便讨论,通过添加中间状态很容易对$P$作出修改使得$P$有唯一的接受状态$q_{accept}$,在$P$接受的时候空栈,每一个转移把一个符号压入栈或者把一个符号弹出栈,但是不能同时做出这两个动作。
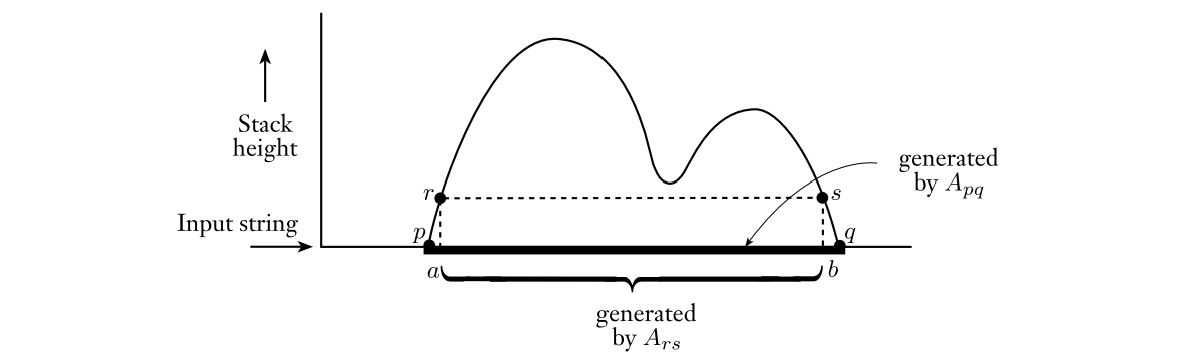
为了找到生成$L$的文法$G$,先考虑设置这样的变量$A_{pq}$,它能产生所有能够让$P$从ID$(p,aw,Z_0)$转移到ID$(q,w,Z_0)$的字符串$a$,这样的字符串自然在栈中还有其他内容的时候也能让$P$实现从状态$p$到状态$q$的转移。
为了知道$A_{pq}$的产生式,首先要考虑它所产生的字符串$x$输入$P$后它所执行的动作。
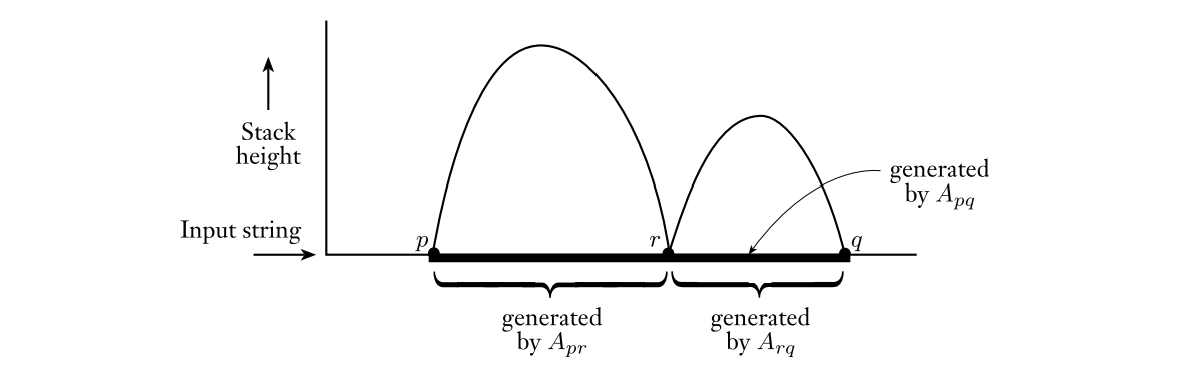
可以知道$P$对$x$的第一个动作一定是压栈、最后一个动作一定是弹栈,那么$P$输入$x$后有两种情况:仅在运算开始和结束的时候$P$存在栈空的情况,在计算的中间过程中存在栈空的情况,很容易想到两个产生式用来模拟这两种情况:$A_{pq}\rightarrow aA_{rs}b$,其中$a,b$就是在开头和结束时读到的输入符号,$r$是紧跟$p$的状态、$s$是$q$前面的那个状态;$A_{pq}\rightarrow A_{pr}A_{rs}$,其中$r$就是中间过程中栈空的状态。下面给出具体的构造方式:
设$P=(Q,\Sigma,\Gamma,\delta,q_0,${$q_{accept}$}$)$,那么可以构造CFG:$G=(${$A_{pq}|p,q\in Q$}$,\Sigma,P’,A_{q_0,q_{accept}})$,其中$P’$满足以下要求:
- 对于$\forall p,q,r,s\in Q,\ u\in\Gamma,\ a,b\in\Sigma\cup${$\epsilon$},如果$(r,s)\in\delta(p,a\epsilon),(q,\epsilon)\in\delta(s,b,u)$,那么$A_{pq}\rightarrow aA_{rs}b\in P’$。
- 对于$\forall p,q,r\in Q$,有$A_{pq}\rightarrow A_{pr}A_{rq}\in P’$。
- 对于$\forall p\in Q$,有$A_{pp}\rightarrow\epsilon$。
可以证明$A_{pq}$产生$x$当且仅当$x$能够让$P$从ID$(p,xw,Z_0)$转移到ID$(q,w,Z_0)$,也就是说对于任何PDA$\ P$,一定存在CFL$ L$使$L=L(P)$,在此不作详细的证明。
综上所述:PDA和CFG是等价的。
CFL的性质
CFL的泵引理
按照先前对乔姆斯基文法体系的介绍可以知道,CFL是CSL的子类,但是不能证明CFL是CSL的真子类。为此需要找到一个语言并且判定它属于CSL而不属于CFL。为了确定一个语言是否不属于某个语言类,很容易想到之前介绍的RL的泵引理,而实际上也有CFL的泵引理,类似于RL的泵引理,它也可以对字符串进行“抽取”而保证字符串在语言当中:
对于任意CFL:$L$,存在仅仅依赖于$L$的正整数$N$(一样也称其为是泵长度),对于$\forall z\in L$,只要$|z|\geq N$时就可以将其分为五部分$z=uvwxy$,满足:
- $|vwx|\leq N$
- $|vx|>0$
- $\forall i\geq 0,uv^iwx^iy\in L$
证明:设CFG:$G=(V,T,P,S)$是接受$L-${$\epsilon$}的CNF,那么在文法$G$的派生树中,如果最长路径为$k$,那么派生出的句子的长度最多为$2^{k-1}$,取$N=2^m,m=|V|$,那么若有$z\in L(G),|z|\geq G$,则$z$的派生树中最长路径长度至少也是$m+1$,同时在这条路径上至少有$m+2$个节点,这条路径经过了$m+1$个内节点,也就是至少有两个节点标记了相同的变量,不妨设这两个节点是$v_1,v_2$,其中前者比后者更加解决树根,以$v_1$为根的子树为$T_1$,以$v_2$为根的子树为$T_2$,设$T_2$的产物是$w$,由于$T_2$是$T_1$的子树,不妨设$T_1$的产物$Z_1=vwx$,那么有$A\Rightarrow^{ * }vAx$和$A\Rightarrow^{ * }w$,也就是说$\forall i\geq 0,A\Rightarrow^{ * }v^iwx^i$,不妨设整棵树的产物$z=uvwxy$,那么有$S\Rightarrow^{ * } uAy\Rightarrow^{ * }uv^iwx^iy\in L$,又知道$T_1$的路径长度不超过$m+1$,也就是说$|vwx|\leq 2^m=N$,最后$T_2$一定处在$B$的树或者$C$的树中,但是$B$和$C$至少产生了一个终结符(这个文法是CNF),也就有$|vx|>0$。
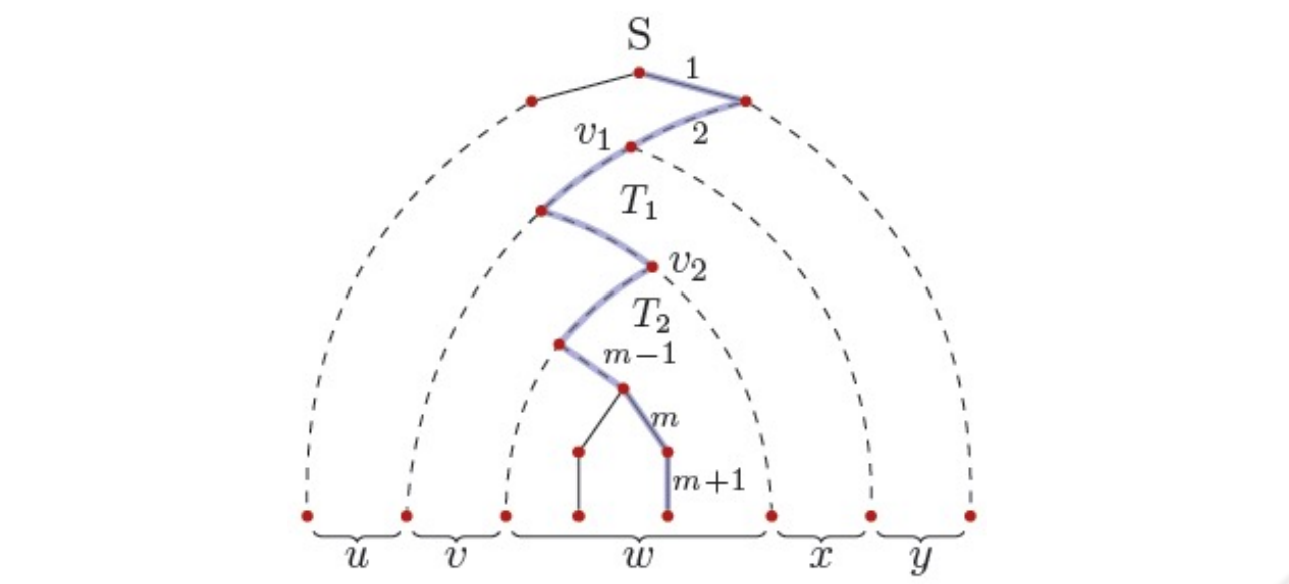
一个有趣的事实是,泵引理其实还可以加强,只要取更大的$N=2^{2m}$,也就是说在它的最长路径上有三个节点标记了相同的变量,利用这三个节点对整个派生树进行划分,通过恰当的选取$u,v,w,x,y$就可以让泵引理的第二个条件更改为$v\neq\epsilon,x\neq\epsilon$。这样就得到了”加强“的泵引理。
前文给出了一个CSG:$G=(${$S,A,B,C$},{$a,b,c$},{$S\rightarrow aBC|aSBC,CB\rightarrow BC,aB\rightarrow ab,bB\rightarrow bb,bC\rightarrow bc,cC\rightarrow cc$}$,S)$,它生成的语言$L(G)=${$a^nb^nc^n|n\geq 1$},利用泵引理可以证明它不是CFL,也就是说CFL类是CSL类的真子类。
前文中提到了一个固有歧义的CFL:$A=${$a^ib^jc^k|i=j或j=k\ i,j,k\geq 0$},在介绍了CFL的泵引理后,现在可以对这一定理进行证明:
证明:一个文法$G$生成了这个语言$A$,$p$是仅依赖于$G$的泵长度,令$k=p!=p(p-1)(p-2)\cdots 1,s=a^kb^kc^k$,现在尝试证明$s$始终有两棵不同的派生树。
令$s_1=a^kb^pc^p,s_2=a^pb^pc^k$,它们是$A$中的字符串,生成它们的派生树是$T_1,T_2$,先考虑$T_1$:
考虑将$T_1$中子节点中叶节点只包含$a$的节点去除,现在证明这样得到的子树必然是只有$2p$个叶子节点的树,而不包含任何$a$作为叶节点:因为$p+p>p$,所以这个子树中有一条路径经过了重复的变量$R$,可以用变量$R$将字符串分成$s=uvxyz$,并且有$|vxy|\leq p$,所以$v$和$y$都只能包含一种字符,否则$uv^2xy^2z\notin A$。同时$y$不可能包含$a$,因为$R$在一条能够生成$a$或$b$或$c$的路径上。因此$v$必须是$b$的字符串、$y$必须是$c$的字符串,并且它们有相同的长度$l$,考虑字符串$vu^dxy^d,d=\frac{k}{l}$,那么这样的字符串的派生树便是要求的子树。 $T_2$也可以同样证明类似的事实,这就说明$s$有两棵不同的派生树,那么生成$A$的文法$G$必须是歧义的文法。
CFL的泵引理只是CFL的必要条件,一个满足CFL的泵引理的语言也可能不是CFL,可以找到这样一个语言$F=${$a^ib^jc^kd^m|i,j,k,m\geq 0且当i=1时有j=k=m$},可以构造$L=${$ab^ic^jd^k|i,j,k\geq 0$},只是一个RL,可知$F\cap L=${$ab^ic^id^i|i\geq 0$},在后文中会证明一个定理:一个CFL和RL的交是CFL,也就是说如果$F$是CFL,那么$F\cap L$也是CFL,而根据泵引理它显然不是CFL,故而$F$并不是CFL。
Ogden引理
有的时候在使用CFL的泵引理时,希望在$v,x$中至少有一个含有某一个“感兴趣”的字符$a$,称这样的字符为特异点(distinguished position) ,为了实现这样的想法,引入Ogden引理:
对于任意CFL$\ L$,存在仅仅依赖于$L$的正整数$N$,对于任意$z\in L$,当$z$中至少含有$N$的特异点时,存在$u,v,w,x,y$使得$z=uvwxy$,并且有:
- $|vwx|$中特异点的个数小于或等于$N$
- $|vx|$中特异点的个数大于或等于$1$
- $\forall i\geq 0,uv^iwx^iy\in L$
证明:设有CFL$\ L$且有$\epsilon\notin L$,从而存在CNF:$G=(V,T,P,S)$使得$L=L(G)$,取$N=2^{|V|}+1$,设$z\in L$,并且$z$中的特异点个数不少于$N$。定义$z$的语法分析树中这样的非叶子节点为 分支点(branch point) :两个儿子的后代均有特异点的节点。
现在构造一条从根节点到叶节点的路径$p$:
- 将根结点放入路径中
- 如果路径上的最后一个点只有一个儿子的后代中有特异点,则将这个儿子放入路径
- 如果路径上的最后一个点的两个儿子的后代中都有特异点,则将特异点多的那个儿子放入路径(相等则任取一个)
- 直到将叶子放入路径为止
显然$p$中至少含有$|V|+1$个分支点,至少有两个不同的分支点标记了相同的变量,选取两个距离叶节点最近的节点$v_1,v_2$并且前者是后者的祖先节点,类似于泵引理证明那样,这两个节点将派生的句子$z$分成了$z=uvwxy$。
注意到路径$p$在$v_1$子树部分所含的分支点的个数小于或等于$|V|+1$,所以$v_1$的结果$vwx$所含的特异点最多为$N$个。再注意到$v_1$是分支点,并且$v_2$是它的后代之一,所以$vx$中至少有一个特异点。那么有$S\Rightarrow^{ * }uAy\Rightarrow^{ + }uvAxy\Rightarrow^{ + }uvwxy$,显然$\forall i\geq 0,S\Rightarrow^{ * }uAy\Rightarrow^{ + }uv^iAx^iy\Rightarrow^{ + }uv^iwx^iy$,也就是说$\forall i\geq 0,uv^iwx^iy\in L$。
证毕。
读者可以尝试使用Ogden引理证明之前提到的语言是固有歧义语言。
CFL的封闭性
为了方便研究CFL类的封闭性问题,先证明CFL类对部分代换的封闭性:
如果有$\Sigma$上的CFL:$L$和代换$s$,且每个$a\in\Sigma$的$s(a)$都是CFL,那么$s(L)$也是CFL。
证明:设$L=L(G),G=(V,T,P,S)$,每一个$s(a)$的文法$G_a=(V_a,T_a,P_a,S_a)$,那么$s(L)$的文法可以构造为$G’=(V\cup(\cup_{a\in T}V_a),\cup_{a\in T}T_a,P’,S)$,其中$P’$包含每一个$P_a$中的产生式和$P$的产生式(但是要替换产生式中的每一个终结符$a$为$S_a$),可以证明$s(L)=L(G’)$。
证明了这一定理后,可以进一步证明CFL类对并、连接、克林闭包、正闭包、同态运算是封闭的:
证明:设$\Sigma={1,2},L_1,L_2$为任意CFL,定义代换$s(1)=L_1,s(2)=L_2$,那么{$1,2$},{$12$},$1^{ * }$和$1^{ + }$显然是CFL,那么就有:
- $s(${$1,2$}$)=s(1)\cup s(2)=L_1\cup L_2$,所以并运算封闭。
- $s(${$12$}$)=s(12)=s(1)s(2)=L_1L_2$,所以连接运算封闭。
- $s(1^{ * })=s(${$\epsilon,1,11,\cdots$}$)=s(\epsilon)\cup s(1)\cup s(11)\cup\cdots=s(\epsilon)\cup s(1)\cup s(1)s(1)\cup\cdots=${$\epsilon$}$\cup L_1\cup L_1L_1\cup\cdots=L_1^{ * }$,所以克林闭包运算封闭。
- $s(1^{ + })=s(${$1,11,\cdots$}$)=s(1)\cup s(11)\cup\cdots=s(1)\cup s(1)s(1)\cup\cdots=L_1\cup L_1L_1\cup\cdots=L_1^{ + }$,所以正闭包运算封闭。
也可以通过构造相应的文法来证明CFL类对并/连接/闭包/反转运算的封闭性:
证明:设CFL$\ L_1,L_2$的文法分别为$G_1=(V_1,T_1,P_1,S_1),G_2=(V_2,T_2,P_2,S_2)$,那么可以构造文法:
- $G_{union}=(V_1\cup V_2\cup${$S$}$,T_1\cup T_2,P_1\cup P_2\cup${$S\rightarrow S_1|S_2$}$,S)$,则$L(G_{union})=L_1\cup L_2$。
- $G_{concat}=(V_1\cup V_2\cup${$S$}$,T_1\cup T_2,P_1\cup P_2\cup${$S\rightarrow S_1S_2$}$,S)$,则$L(G_{concat})=L_1L_2$。
- $G_{closure}=(V_1\cup${$S$}$,T_1,P_1\cup${$S\rightarrow S_1S|\epsilon$}$,S)$,则$L(G_{closure})=L_1^{ * }$。
- $G_R=(V,T,${$A\rightarrow\alpha^R|A\rightarrow\alpha\in P$}$,S)$,则$L(G_R)=L^R$。
CFL类对同态运算封闭。
证明:若$h$是$\Sigma$上的同态,$L$是$\Sigma$上的CFL,对于$\forall a\in\Sigma$,令代换$s’(a)=${$h(a)$},则$h(L)=${$h(w)|w\in L$}$=\cup_{w\in L}${$h(w)$}$=\cup_{w\in L}s’(w)=s’(L)$,所以同态运算封闭。
CFL类对逆同态运算封闭。
证明:如果$L$是字母表$\Delta$上的CFL,$h$是字母表$\Sigma$到$\Delta^{ * }$的同态,那么$h^{-1}(L)$也是CFL。
设有PDA:$P=(Q,\Delta,\Gamma,\delta,q_0,Z_0,F),L(P)=L$,可以构造PDA满足$L(P’)=h^{-1}(L)$,在构造中可以利用设置状态以模拟缓冲(Buffer)用于暂存字符$a\in\Sigma$的同态串$h(a)$:
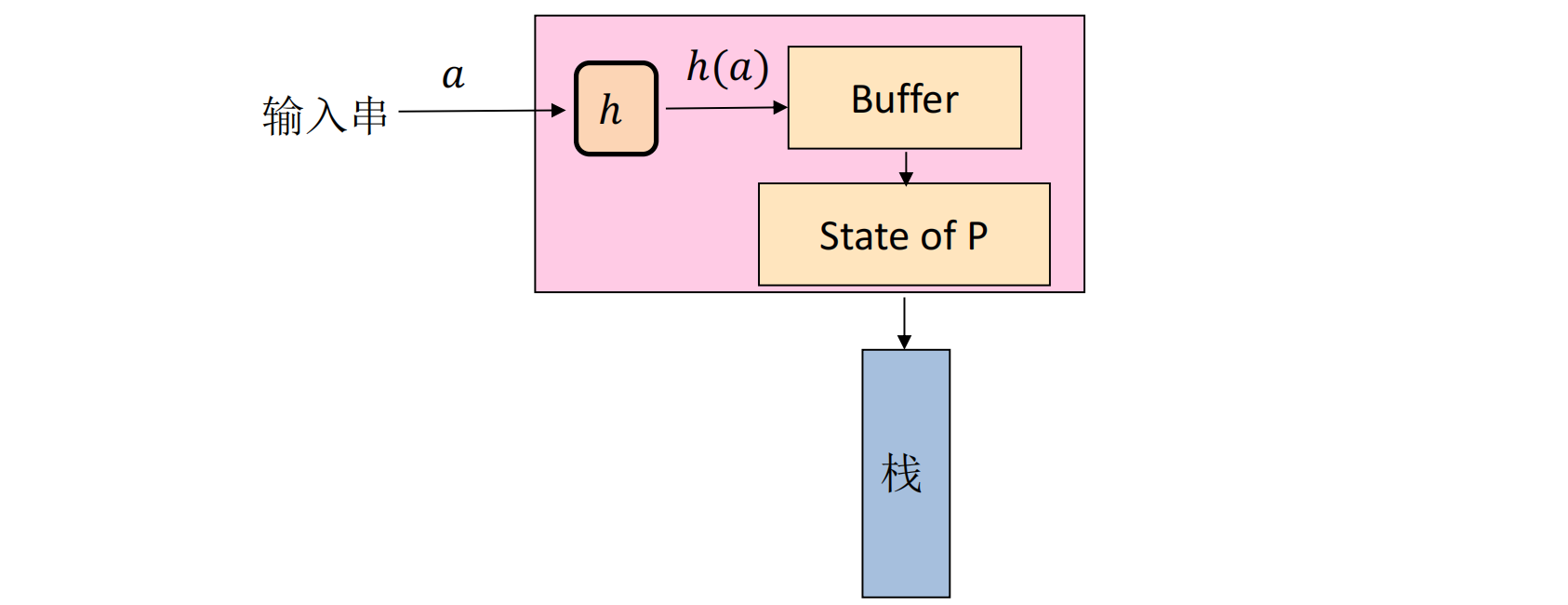
可以构造这样的PDA:$P’=(Q’,\Sigma,\Gamma,\delta’,[q_0,\epsilon],Z_0,F\times${$\epsilon$}$)$
- $Q’$中的状态为$[q,x],q\in Q$,即$P$的状态和缓冲中还未被消耗的串$x$,也即某个$h(a)$的后缀。
- 设$q\in Q$,那么$\forall [q,\epsilon]\in Q\times${$\epsilon$}$,\forall a\in\Sigma,\forall X\in\Gamma,\delta’([q,\epsilon],a,X)=${$([q,h(a)],X)$},也就是将$h(a)$装载到缓冲中的过程。
- 模拟$P$处理在缓冲中储存的$h(a)$的过程:$\forall b\in\Delta\cup${$\epsilon$},如果有$\delta(q,b,X)=${$(p_1,\beta_1),\cdots,(p_k,\beta_k)$},则有$\delta’([q,bx],\epsilon,X)=${$([p_1,x],\beta_1),\cdots,([p_k,x],\beta_k)$},这里的$x$是某个$h(a)$的后缀。
和RL类不同,CFL类在交运算下不是封闭的,证明如下:
证明:考虑$L_1={0^n1^n2^i|i,n\geq 1}$,$L_2={0^i1^n2^n|i,n\geq 1}$,它们显然是CFL,但是$L_1\cap L_2={0^n1^n2^n|n\geq 1}$,这不是一个CFL,同样地CFL类在补运算下也不封闭(考虑$L_1\cap L_2=\overline{\overline{L_1}\cup\overline{L_2}}$)。
但是如果$L$是CFL且$R$是正则语言,则$L\cap R$是CFL,证明如下:
设有DFA:$D=(Q_1,\Sigma,\delta_1,q_1,F_1)$和PDA:$P=(Q_2,\Sigma,\Gamma,\delta_2,q_2,Z_0,F_2)$,同时有$L(D)=R,L(P)=L$,那么可以构造接受$L\cap R$的PDA:$P’=(Q_1\times Q_2,\Sigma,\Gamma,\delta,(q_1,q_2),Z_0,F_1\times F_2)$,其中$\delta$满足下列条件:
- $\delta((p,q),a,Z)={((p,s),\beta)|(s,\beta)\in\delta_2(q,a,Z)}$,若有$a=\epsilon$。
- $\delta((p,q),a,Z)={((r,s),\beta)|r=\delta_1(p,a)且(s,\beta)\in\delta_2(q,a,Z)}$,若有$a\neq\epsilon$。
CFL的判定性质
关于CFL的判定性质,在此进行简单的说明:
判定一个CFL是否为空就是看生成它的文法的起始符号是否为无用符号,如果起始符号为无用符号,那么语言为空。
判定一个CFL是否为无穷语言,先作出CFL$\ L$对应的文法$G=(V,T,P,S)$,并且去除$G$的无用符号,再用一张有向图来表示$G$,其中图的顶点为$G$中的变量,如果$A\rightarrow B\in P$,那么在图中增加一条从$A$到$B$的边,图的源点为$S$,如果图中存在可以从源点出发到达的环,那么这个CFL是一个无穷语言。
判定一个字符串是否属于CFL可以使用CYK算法,在这里不对CYK算法进行说明。
确定性上下文无关语言
确定性下推自动机的形式化定义
在程序设计语言编译器中要设计语法分析器,而通常来说,与CFL相比,对 确定型上下文无关语言(Deterministic context free languague,DCFL) 进行语法分析要更加容易,能够被 确定性下推自动机(Deterministic pushdown automata,DPDA) 识别的语言就是DCFL,构造DPDA也就要在PDA的基础上遵循确定性的基本原则:在计算的每一步,根据其转移函数,DPDA只有一种继续的方式,但是定义DPDA比定义DFA更加复杂,因为DPDA可能在不弹出栈符号的情况下读入输入符号,反之也是这样。同样在DPDA的转移函数中存在$\epsilon$-转移:$\epsilon$-输入转移($\epsilon$-in-put move)对应于$\delta(q,\epsilon,x)$,$\epsilon$-栈转移($\epsilon$-stack move)对应于$\delta(q,a,\epsilon)$,当然也允许$\delta(q,\epsilon,\epsilon)$。但是一台DPDA不能同时做出多个动作,现在给出DPDA的形式化定义:
DPDA是一个七元组$P=(Q,\Sigma,\Gamma,\delta,q_0,Z_0,F)$,它在满足PDA的形式化定义的前提下还要求满足下列条件:
- 对于$\forall q\in Q,a\in\Sigma\cup${$\epsilon$}$,x\in\Gamma,\delta(q,a,x)$至多只能含有一个元素。
- 对于$\forall q\in Q,x\in\Gamma$,如果有$\delta(q,\epsilon,x)\neq\varnothing$,那么对于$\forall a\in\Sigma$都有$\delta(q,a,x)=\varnothing$。
DPDA接受一个语言有两种标准:以空栈形式接受和以最终状态接受,这两种方式接受的语言都是非固有歧义的CFL,但是并非所有非固有歧义的CFL都可以被DPDA接受,例如$L(G)$,其中$G=${{$S$},{$0,1$},{$S\rightarrow 0S0|1S1|\epsilon$}$,S$}。
不同于PDA,对于DPDA而言这两种接受方式是不等价的(以空栈形式接受的语言是以最终状态接受的并且满足无前缀性质的语言),故而使用最终状态作为接受标准来定义DCFL。
如果DPDA在读入字符串的最后一个符号后进入接受状态则接受这个字符串,在其他任何情况下都拒绝这个字符串,也就意味着有两种情况会发生拒绝:要么DPDA读完了全部输入但是无法进入接受状态,要么DPDA没有成功读完全部输入字符串。
两种特殊情况会导致DPDA无法成功读完全部输入字符串:DPDA试图弹出空栈(hanging)和DPDA执行无尽的$\epsilon$-转移序列,通过对DPDA进行适当的修改,可以让可能发生这两种情况的DPDA都转为能够读完整个输入字符串的等价DPDA。
为了简化讨论,可以将一个特定标记符号$\dashv$放到输入字符串的末尾,称其为 输入结束标记(endmarked input) ,可以证明添加这一个标记不会改变DPDA的能力(也就是说接受的语言依旧是DCFL),然而这为简化设计DPDA提供了帮助,使用结束标记语言$A\dashv$表示字符串$w\dashv,w\in A$的集合。
很容易构造出DPDA接受语言{$0^n1^n|n\geq 0$},也就是说RL类是DCFL类的真子类。但是现在还无法判断DCFL类是否是CFL类的真子类,为此不妨考虑DCFL的封闭性,现在说明DCFL对运算的封闭性。
DCFL的封闭性
DCFL类在补运算下封闭。
证明:简单地类比DFA交换接受状态和非接受状态的证明是错误的,因为在输入字符串的末端,DPDA进入转移序列的接受和非接受状态都可能接受输入,在这种情况下,交换接受状态和非接受状态依旧会发生接受。不妨将DPDA:$P=(Q,\Sigma,\Gamma,\delta,q_0,Z_0,F)$修改为总是读入全部输入字符串、同时一旦进入一个接受状态它将会停留在接受状态直到读入下一个输入符号。现在给出一种可行的构造:如果DPDA读入字符并且没有弹栈($\delta(q,a,\epsilon)\neq\varnothing$),可以称这样一个状态$q$是一个“读入状态”,倘若弹栈了,也就是说$\delta(q,a,x)=(r,w_1w_2\cdots w_n)$,那么不妨新增状态并修改$\delta$使得$\delta(q,\epsilon,x)=\delta(q_{w_1},\epsilon),\delta(q_{w_1},\epsilon)=(q_{w_2},w_1),\cdots,\delta(q_{w_n},\epsilon)=(r,w_n)$,那么认定$q_{w_1},q_{w_2},\cdots,q_{w_n}$都是“读入状态”,如果又有$q\in F$,则认定它们都是接受状态。最后从所有非读入状态中移除接受状态的认定,这样再将接受状态和非接受状态互换就可以得到接受DCFL的补的DPDA。
这个事实说明一些CFL并不是DCFL,如果CFL的补不是一个CFL,那么它就不是一个DCFL,例如$A=${$a^ib^jc^k|i,j,k\geq 0,i\neq j或j\neq k$}便不是一个DCFL但它是一个CFL,否则$\overline{A}\cap${$a^ib^jc^k|a,b,c\geq 0$}={$a^nb^nc^n|n\geq 0$}将是一个CFL。
DCFL类在并运算下不封闭。
证明:可以构造$L_1=${$a^ib^c^k|i,j,k\geq 0且i\neq j$}$,L_2=${$a^ib^jc^k|i,j,k\geq 0且j\neq k$},可以构造DPDA识别这两个语言,故而它们都是DCFL,但是有$L_1\cup L_2=${$a^ib^jc^k|i,j,k\geq 0,i\neq j或j\neq k$},在先前已经证明了它不是一个DCFL,故DCFL类在并运算下不封闭。
DCFL类在交运算下不封闭。
证明:考虑$L_1\cup L_2=\overline{(\overline{L_1}\cap\overline{L_2})}$,由于DCFL类在补运算下封闭、在并运算下封闭,所以DCFL类在交运算下不封闭。
虽然DCFL类在交运算下不封闭,但是类似于CFL类,DCFL与RL的交是一个DCFL,证明如下:
证明:考虑有DFA:$D=(Q_1,\Sigma_1,\delta_1,q_{s1},F_1)$和DPDA:$P=(Q_2,\Sigma,\Gamma,\delta_2,q_{s2},Z_0,F_2)$,那么可以构造DPDA:$P’=(Q_1\times Q_2,\Sigma,\Gamma,\delta_3,(q_{s1},q_{s2}),Z_0,F_1\times F_2)$,其中$\delta_3$为$(Q_1\times Q_2)\times\Sigma\times\Gamma\rightarrow(Q_1\times Q_2)\times\Gamma^{ * }$的函数,并且满足$\forall q_1\in Q_1,\forall q_2\in Q_2,\delta_3((q_1,q_2),a,b)=(\delta_1(q_1,a),\delta_2(q_2,a,b))$,这样一个DPDA识别的语言是$L_1\cap L_2$,也就说明DCFL与RL的交是一个DCFL。
DCFL类在连接运算下不封闭。
证明:设$L_1=${$a^ib^jc^k|i,j,l\geq 0,i\neq j$},$L_2=${$a^ib^jc^k|i,j,k\geq 0,i\neq k$},$L_3=({d}L_1)\cup L_2$,很容易构造识别$L_3$的DPDA,也就是说$L_3$是DCFL,已知$d^{ * }$为DCFL,不妨设DCFL类在连接运算下封闭,也就是说$d^{ * }L_3$是DCFL,已知$L_4=${$da^ib^jc^k|i,j,k\geq 0$},它是一个RL,也就是说$d^{ * }L_3\cap L_4$是一个DCFL,但是有$d^{ * }L_3\cap L_4=dL_1\cup dL_2=d(L_1\cup L_2)$,$L_1\cup L_2$不是DCFL,显然$d(L_1\cup L_2)$不是DCFL,矛盾,得证。
DCFL类在克林闭包运算下不封闭。
证明:设$L_1=${$a^ib^jc^k|i,j,l\geq 0,i\neq j$},$L_2=${$a^ib^jc^k|i,j,k\geq 0,i\neq k$},$L_3={$d$}\cup${$d$}$L_1\cup L_2$,考虑$L_3^{ * }\cap${$d^{ * }$}$(${$a^{ * }$}{$b^{ * }$}{$c^{ * }$}-{$\epsilon$}$)=${$d$}$(L_1\cup L_2)$,如果DCFL类在克林闭包运算下封闭,则导出矛盾,得证。
DCFL类在反转运算下不封闭。
证明:设$L_1=(a+b+c)^{ * }wcw^R,L_2=wcw^R(a+b+c)^{ * },w\in(a+b)^{ + }$,前者不是DCFL,但是反转后得到后者却是DCFL,得证。
确定性上下文无关文法
在先前的分析中,多考虑的是派生的过程,而为了引出确定性上下文无关文法,要考虑的是归约的过程。
对以$S$为起始变元的CFG,串$w$属于它的语言,设$w$的最左归约为:$w=u_1\mapsto u_2\mapsto\cdots\mapsto u_k=S$,如果要确保“确定性”,规定$u_i$决定了下一个步骤$u_{i+1}$,因此$w$决定了整个归约过程,但这只能说明无歧义,因而要进一步要求对于每一个$u_i$,下一个归约步骤必须由$u_i$的前缀唯一确定,且此前缀从头开始并且包含了归约步骤中的归约串(也就是被替换的串,reducing string)$h$。
令$w$是属于CFG:$G$的一个字符串,$u_i$出现在$w$的最左归约中,在归约步骤$u_i\mapsto u_{i+1}$中称产生式$T\rightarrow h$被反向运用。也就是说可以记作$u_i=xhy,u_{i+1}=xTy$,其中$h$是归约串,$x$是$u_i$的一部分并且出现在$h$的左侧,$y$是$u_i$的一部分并且出现在$h$的右侧,也就是有$u_i=x_1\cdots x_jh_1\cdots h_jy_1\cdots y_l\mapsto x_1\cdots x_jTy_1\cdots y_l=u_{i+1}$,现在定义$h$和和它相关的产生式$T\rightarrow h$称为是$u_i$的一个 句柄(handle) ,在不关注产生式的情况下也可以特指归约串,为方便起见,定义句柄的时候只需要考虑$L(G)$中的句子的最左归约,称归约过程中出现的字符串为 有效串(valid string) 。
考虑文法$G_1=(${$R,S,T$},{$a,b$},{$R\rightarrow S|T,S\rightarrow aSb|ab,T\rightarrow aTbb|abb$}$)$,很明显它识别的语言是$A\cup B,A=${$a^mb^m|m\geq 1$}$,B=${$a^mb^{2m}|m\geq 1$},很容易利用PDA的不确定性来识别$L(G_1)$,它将会猜测输入是$B$中的字符串亦或者是$C$中的字符串,它在将$a$压入栈中后将弹出句柄并尝试用句柄匹配$b$或者$bb$。但是对于DPDA而言它不能预先知道输入属于哪个集合,自然不知道如何匹配句柄,实际上可以证明$L(G_1)$不是DCFL。
从这样一个例子可以发现句柄起着非常重要的作用,为了让DCFG和DPDA相对应,自然要对句柄作出限制。某个串可能有多个句柄的歧义性语法,选择一个特定的句柄可能需要预先知道语法分析树产生了这个串,以及那些对于DPDA一定是无法获得的信息。很明显DCFG理应是非歧义性的,因而句柄是独一无二的,然而独一无二的句柄并不够定义DCFG,考虑刚刚定义的文法$G_1$产生的句子$aabb,aabbbb$,确定这样两个字符串的句柄还需要读完整个输入。
所以要对句柄施加一个额外的要求:一个有效串的初始部分必须足以决定句柄,也就是说读入有效串的过程中一旦读入了句柄就可以确定获得了句柄,因此,在每一个有效串$xh\hat{y},\hat{y}\in\Sigma^{ * }$中$h$是独一无二的句柄时,那么称$h$是有效串$v=xhy$的一个 强制句柄(forced handle) 。
现在可以给出DCFG的定义了: 确定性上下文无关文法(deterministic context free grammar,DCFG) 是能够让每一个有效串都有一个强制句柄的上下文无关文法。
已经有了DCFG在数学上的精确定义,但是却无法判断一个CFG是否是DCFG,下文将提供一个能够准确实现整个目的的过程,称之为$DK$-测试,它依赖于一个简单但令人惊讶的定理:对于任意CFG:$G$都能够构造一个可以识别句柄的关联DFA:$DK$,如果满足以下条件,$DK$将接受它的输入:
- $z$是某个有效串$v=zy$的前缀。
- $z$以$v$的一个句柄作为结束。
首先考虑这样一个NFA:$J$,它接受每一个以任何产生式的右部作为结束的输入串,构造$J$是相当容易的:
$J$将猜测哪个产生式可以适用,也能猜测从何处开始将输入和产生式的右部相匹配,随着匹配输入,$J$通过已经选好的产生式的右部来追踪它的进程,在这个产生式的右部的对应位置放置句点以表示这个进程,称为加点规则(dotted rule)/项(item),对于$B\rightarrow u_1u_2\cdots u_k$将会产生$k+1$个加点规则:$B\rightarrow.u_1u_2\cdots u_k,B\rightarrow u_1.u_2\cdots u_k,B\rightarrow u_1u_2\cdots.u_k,B\rightarrow u_1u_2\cdots u_k.$。
每一个加点规则都对应于$J$的一个状态,句点到产生式末尾时称为是完整规则(completed rule),它对应着$J$的接受状态,它没有向外的转换。
对于每一个规则$B\rightarrow u$,为$B\rightarrow.u$添加一个单独的由所有符号的自循环构成的起始状态和从起始状态到这个状态的$\epsilon$-转移,这样便完成了$J$的构造。
现在引入NFA:$K$,它以相似但简捷的方式选择匹配规则,只有可能的归约规则才会被允许。和$J$一样它的状态对应于所有加点规则,接受状态对应着完整规则,它没有向外的转换。它有一个特殊的起始状态$S_1$,该状态对所有包含起始变元$S_1$的规则来说都有到$S_1\rightarrow.u$的$\epsilon$-转移,$K$的转移函数$\delta$满足:
- 如果有产生式$B\rightarrow uav$,那么{$B\rightarrow ua.v$}$\subseteq\delta(B\rightarrow u.av,a)$。
- 如果有产生式$B\rightarrow uCv,C\rightarrow r$,那么{$C\rightarrow.r$}$\subseteq\delta(B\rightarrow u.Cv,\epsilon)$。
可以证明:
在输入$z$上$K$可能进入状态$T\rightarrow u.v$当且仅当对于某些$y\in\Sigma^{ * },z=xu$且$xuvy$是一个句柄为$uv$、归约规则为$T\rightarrow uv$的有效串。也就是说在输入$z$上$K$可能进入接受状态$T\rightarrow h.$当且仅当$z=xh$且$h$是遵循归约规则$T\rightarrow h$的有效串$xhy$的一个句柄。
之前已经证明了可以利用子集构造法的方式将一个NFA转换成DFA,现在用子集构造法将$K$转换成$DK$,每一个$DK$的状态包含若干个加点规则,每一个接受状态包含至少一个完整规则,上面的定理依旧可以被应用。现在给出$DK$-测试:
从一个CFG:$G$开始构造关联的DFA:$DK$,通过检查$DK$的接受状态,判定$G$是否是DCFG,通过$DK$-测试要求每一个接受状态包含:
- 有且仅有一个完整规则。
- 所有加点规则中句点不会紧跟着一个终结符,即没有形如$B\rightarrow u.av,a\in\Sigma^{ * }$的加点规则。
可以证明$G$通过$DK$-测试当且仅当$G$是一个DCFG。
在实际运用中直接构建$DK$会比事先构造$K$再将其转为NFA更快,下面给出对$G_1=(${$S,E,T$},{$a,+,\times,\dashv$},{$S\rightarrow E\dashv,E\rightarrow E+T|T,T\rightarrow T\times a|a$}$,S)$使用$DK$-测试的结果。
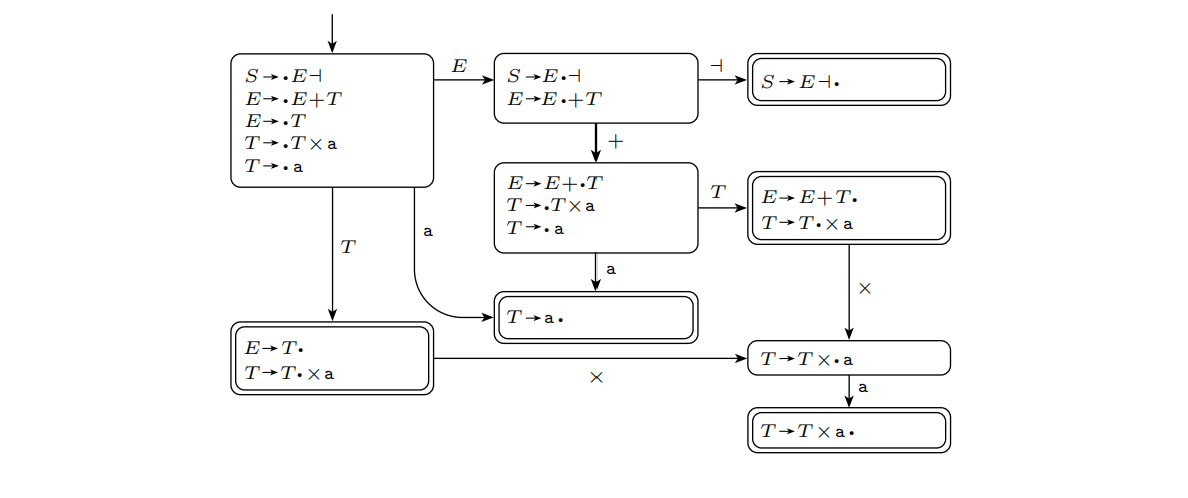
可以看到左下侧和右上侧这两个接受状态不符合$DK$-测试的要求,也就是说这个文法不是DCFG。
再对文法$G_2=${{$S,T$},{$\dashv,(,)$},{$S\rightarrow T\dashv,T\rightarrow T(T)|\epsilon$}$,S$}使用$DK$-测试。
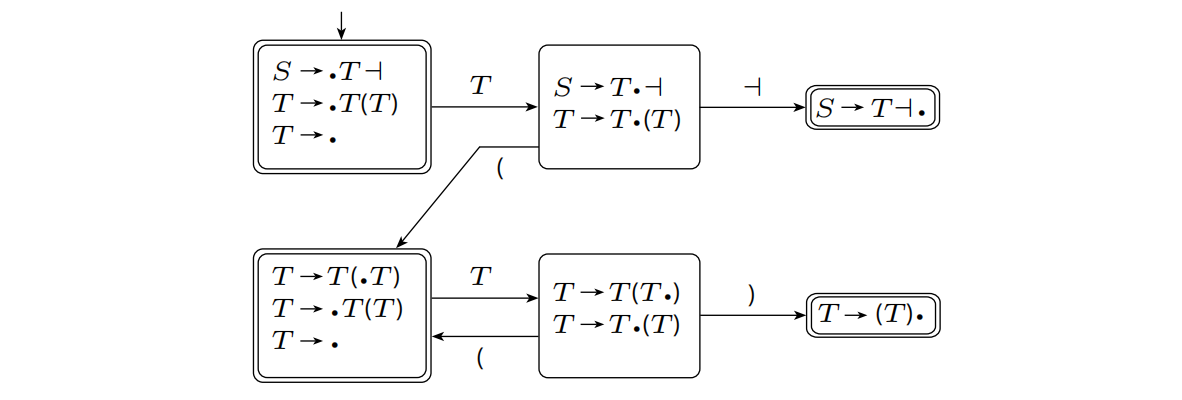
这个文法对应的$DK$的所有接受状态都满足$DK$-测试的条件,也就是说这个文法是DCFG。
DPDA和DCFG的等价性
之前已经证明了结束标记不会影响DPDA识别的语言类,但是它会影响DCFG产生的语言类。如果没有结束标记,DCFG只会产生DCFL的一个子类————它们都是前缀无关的,值得注意的是所有结束标记语言都是前缀无关的。
每一个DCFG都有一个等价的DPDA。
证明:考虑这样的$P$,它将利用之前构造的$DK$进行操作,对于从输入中所读取的符号,它模拟$DK$直到$DK$接受,$DK$的接受状态指明一个特定的加点规则,因为$G$是确定性的,并且这个规则为扩展了目前已知输入的有效串确定一个句柄。此外,因为$G$是确定性的,这个句柄适用于每一个有效扩展,特别地如果输入属于$L(G)$,那么这个句柄适用于对$P$的全部输入。所以$P$能使用这个句柄为它的输入串确定第一个归约步骤,尽管在此时它只是读入了它输入的一部分。为了让$P$执行接下来的归约步骤,可以在栈中存储所有$DK$的状态,当$P$读入一个输入符号并模拟一个在$DK$中的转移时,它通过将其压入栈来记录$DK$的状态。当其使用归约规则$T\rightarrow u$来执行一个归约步骤时,它从栈中弹出$|u|$个状态,展现在读入$u$之前$DK$的状态。它将$DK$重置为该状态,接下来在输入$T$上模拟$DK$,并将产生的状态压入栈,之后$P$像之前读取和处理输入符号那样继续进行。当$P$将起始变元压入栈时,表明它已经找到了一个输入到起始变元的归约,那么进入一个接受状态。
对于每一个能够识别结束标记语言的DPDA都有一个等价的DCFG。
证明:设DPDA:$P=(Q,\Sigma,\Gamma,\delta,q_0,Z_0,${$q_a$}$)$,构造CFG:$G$,其起始变元为$A_{q_0,q_a}$,其产生式按照以下规则产生:
- 对于$\forall p,q,r,s,t\in Q,\forall u\in\Gamma,\forall a,b\in\Sigma_{\epsilon}$,如果$\delta(r,a,\epsilon)=(s,u)$且$\delta(t,b,u)=(q,\epsilon)$,则$A_{pq}\rightarrow A_{pr}aA_{st}b$是$G$的产生式。
- 对于$\forall p\in Q$,$A_{pp}\rightarrow\epsilon$是$G$的产生式。
可以证明如果$P$读入包含一个变量$A_{pq}$的$v_i$,那么它正好在读入$A_{pq}$之前进入状态$p$,从而可以证明$G$可以通过$DK$-测试,也就是说这样构造的CFG是一个DCFG。
可以得到这样的结论:一个结束标记语言是DCFL当且仅当它可以由一个DCFG产生。
LR(k)文法
DCFG有时在表达特殊的DCFL时并不方便,其要求所有句柄都是强制句柄,这限制了设计直观的DCFG,解决这一问题可以考虑一个叫做LR(k)的宽泛文法类(首字母的缩略词表示Left to right input processing,Rightmost derivation),它和DCFG非常相似,都允许到DPDA的直接转变,这个文法的赛诺菲引入了前瞻性(lookahead),它的句柄也可能依赖于该句柄后的前$k$个符号。
令$h$是有效串$v=xhy$的一个句柄,如果$h$对每一个有效串$x\hat{h}y$($xh\hat{y}$满足$\hat{y}\in\Sigma^{ * }$且$y$和$\hat{y}$在它们的前$k$个符号上是一致的)来说是独一无二的句柄,那么称$h$是 被前瞻k所强制的(forced by lookahead k) 。(如果其中某个串的长度小于$k$,那么一致的长度和这个短串的长度相同)
现在给出对LR(k)文法的定义:LR(k)文法是一种每一个有效串的句柄都是被前瞻$k$所强制的上下文无关语法。
LR(0)文法实际上就是DCFG,同时也能证明对于任何一个$k$,都能将文法LR(k)转换为DPDA,也就是说LR(k)文法对所有$k$和所有DCFL的准确描述在能力上是等价的。
类似于DCFG,现在给出$DK_1$-测试(前瞻为1的$DK$-测试)的定义,先构造一个NFA:$K_1$并将其转换成DFA:$DK_1$。$K_1$的每一个状态是一个加点规则$T\rightarrow u.v$和称为 前瞻符号(lookahead symbol) 的终结符$a$构成的二元组,这说明$K_1$最近读入了串$u$,如果$v$在$u$后出现并且$a$在$v$之后出现,那么$u$可能为句柄$uv$的一部分。
对每一个包括起始变元$S_1$和所有$a\in\Sigma$的产生式,开始状态有个到$(S_1\rightarrow.u,a)$的$\epsilon$-转移,同样也有{$(T\rightarrow ux.v,a)$}$\subseteq\delta((T\rightarrow u.xv,a),x)$和{$(C\rightarrow.r,b)$}$\subseteq\delta((T\rightarrow u.Cv,a),\epsilon)$,这里的$b$是能从$v$中派生出来的任意终结符串的第一个符号。如果$v$派生出$\epsilon$,那么添加$b=a$。对完整规则$B\rightarrow u.$和$a\in\Sigma$,所有的接受状态都是$(B\rightarrow u.,a)$。
令$R_1$是带前瞻符号$a_1$的完整规则,$R_2$是带前瞻符号$a_2$的加点规则,满足以下其中任意一个条件则称$R_1,R_2$是 一致的(consistent) ,如果有:
- $R_2$是完整的且$a_1=a_2$。
- $R_2$不是完整的且$a_1$紧跟在句点后面。
那么$DK_1$-测试就是将$K_1$转换成DFA并且要求每一个接受状态一定不包含任意两个一致的加点规则。可以证明文法$G$通过$DK_1$测试当且仅当$G$是一个LR(1)文法。考虑文法$G_1=(${$S,E,T$},{$a,+,\times,\dashv$},{$S\rightarrow E\dashv,E\rightarrow E+T|T,T\rightarrow T\times a|a$}$,S)$,对它使用$DK_1$-测试,那么有:
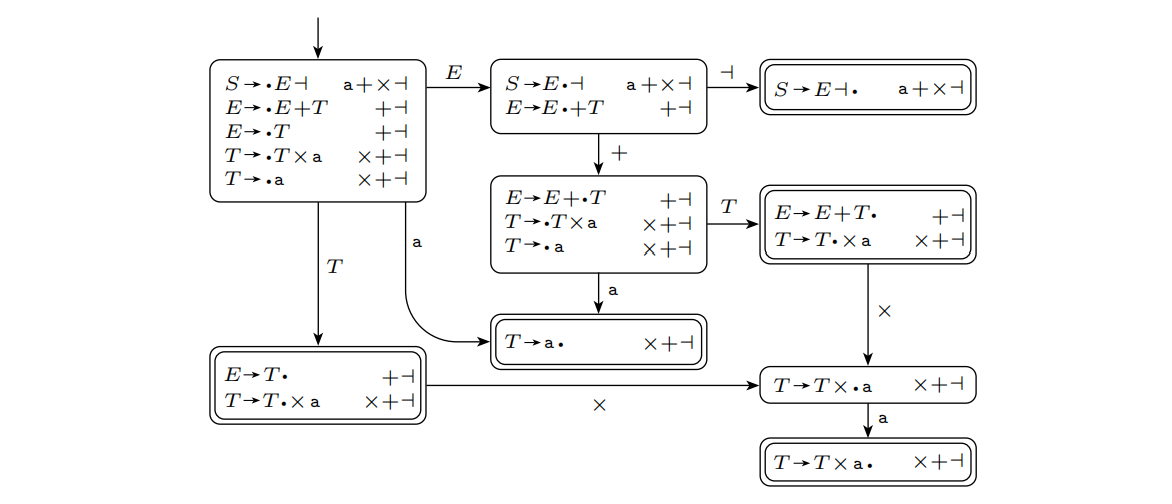
可以知道它是一个LR(1)文法而非DCFG。